Dealing with a cyber-attack: lessons learnt
We faced a major cyber-attack on 5th May. Here are the lessons we learnt.
May 06, 2020
I run a service that provides automated content to large publishers. Yesterday, we faced a major cyberattack. There were about 25 million excess requests on our site (requests above normal levels) in 24 hours, with 8 million excess requests in just one hour. Luckily no harm was done – mostly thanks to CloudFlare and fortuitous design choices. Our public facing site is a simple Google Cloud Storage bucket that cannot make any requests to our server, so we were spared the ignominy of a our systems going down under traffic.
What happened
Between 1-2PM SGT (5-6AM GMT) on May 5, we received a massive surge of requests from a network of Tor bots (we saw an additional 8 million requests in an hour). At the peak of this, we saw around ten thousand requests hit our bucket every second.
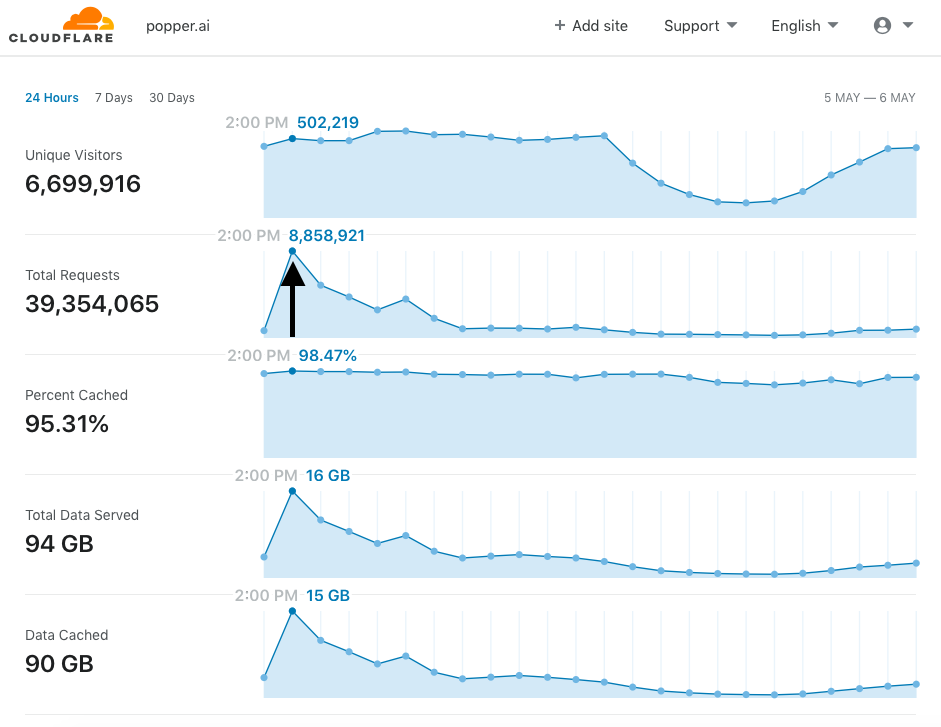
Most of the these requests made in the first hour were 404s. After examining the logs, we realized that the attacker was trying out random URLs in hopes of getting access to the data stored on the bucket. After the first hour, the proportion of 404s kept decreasing as the attacker began to figure out which URL structures yielded results and which did not.
The attacker first tried using a bunch of PUT requests and tried to access fields that may have held sensitive information (like /.git/*. When this did not work, they tried out random URLs, and doubled down on all URL path components that did not return a 404 error.
How was this discovered
I discovered this around midnight my time after seeing a spike in requests. At this point, Cloudflare had automatically begun to issue challenges to some visitors, but many other IPs were still crawling the site. After I dug into the data, a few things became clear.
First, a fairly large Tor network was being used for this. The majority (80+%) of suspicious requests came through Tor.
Second, those not using Tor were using a network of rotating IPs and user-agents. The majority of these suspicious requests appeared to originate from a rotating cast of countries – of which Nigeria, India, Indonesia, Bangladesh, and Ethiopia were most prominent. A large number of requests (250k+) also came from what Cloudflare classified as "Unknown states, other entities or organizations".
Third, after I instituted rules for blocking Tor and certain IPs (more on this later), the attacker switched tactics to using the User-Agent string of a Google bot. Thankfully, this was automatically blocked by CloudFlare.
How this was resolved
While Cloudflare was automatically issuing captcha challenges to a small proportion of suspicious requests, I decided to institute some rules to block suspicious users. This had a clear impact on the number of attempts blocked or challenged.
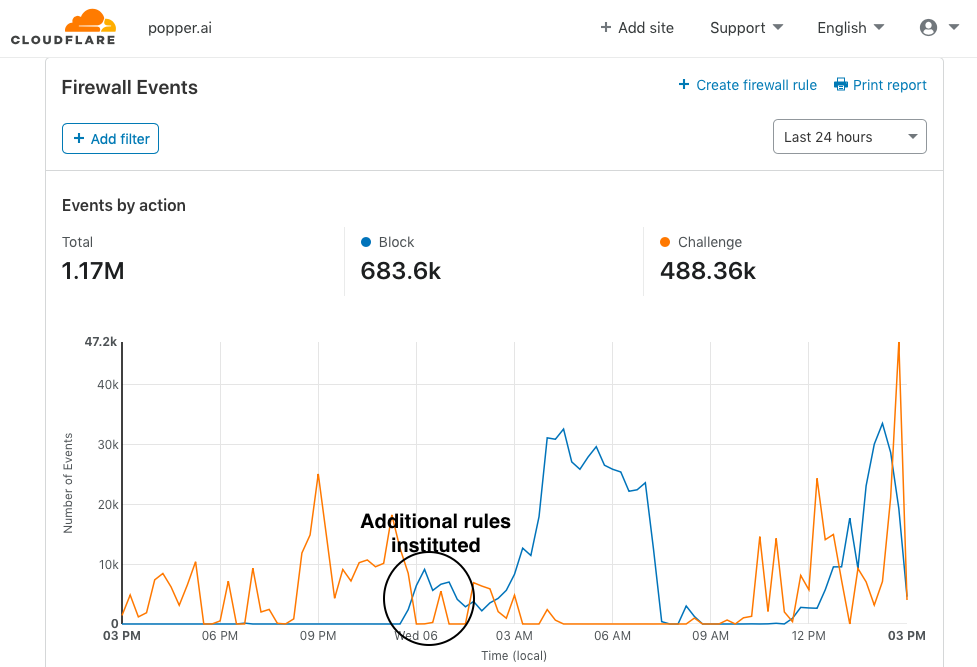
First, I blocked all Tor users. The vast majority of suspicious activity was coming from Tor. While some privacy focused users swear by Tor, they are a tiny proportion (less than 1 in a million) of those who request our content. This was a no-brainer to implement.
Second, I manually blocked IPs that had made more than 30,000 requests in an hour using Cloudflare's firewall rules.
Lastly, I changed my Cloudflare security level from Medium to High. This automatically increased the proportion of visitors that were issued a captcha challenge.
The aftermath
While suspicious attempts continue even after the 24 hours, the total number of requests made to our bucket have (more or less) returned to normal. Most of the bots attempting to hit our bucket seem to now be blocked or challenged by Cloudflare. Incredibly impressed by Cloudflare's ability to seamlessly deal with this.
I had also made an early choice to not expose any of my SQL servers and virtual machines to HTTP or HTTPS traffic, which ended up being a lifesaver. All of our analytics are captured through Google Cloud Functions and go straight to BiqQuery, with no interactions with an SQL server or any other VM. This ended up being a fairly fortuitous architecture decision, and made sure that our system was not overwhelmed by this in any significant way (except for slightly higher costs from Google Cloud Storage).
Have feedback, or open to sharing your own experiences?
If you have feedback about this post, or want to share your own cybersecurity stories, please @ me on Twitter at @rishdotblog.